
The Last Human Data
Synthetic data may make medicine look more complete. But it cannot recover the missing signal of women’s bodies - Panel July 7th, WSIS, Geneva

Artificial intelligence is running out of fresh human context.
Not data in general. There will always be more data: more text, more images, more clicks, more synthetic records, more machine-generated content. What AI is running out of is the harder thing to replace: high-quality human signal from real lives, real bodies, real decisions, real symptoms, real relationships, and real environments.
Data is the record a system already knows how to store.
Context is what explains why that record matters.
A billing code is data. A symptom pattern unfolding over years is context. A click is data. The hesitation, trust, desire, or constraint behind it is context. A diagnosis is data. The years before the diagnosis, when the pattern was present but not yet legible to the system, are context.
AI does not learn from reality directly. It learns from what systems have made legible. That is why the next frontier is not simply more data. It is better instruments for capturing context.
Researchers at Epoch AI estimate that the supply of public human-generated text may be exhausted sometime between 2026 and 2032, with the highest-quality sources disappearing first.
By 2026, the open web is no longer a clean source of human expression. A meaningful share of it is already machine-produced, so even models trained on new crawls are increasingly drinking their own exhaust.
So the industry has chosen the obvious answer : synthetic data.
Models will generate the data that trains the next models. The loop will continue, and the machine will feed itself.
The Problem With Synthetic Data When It Comes To Women’s Health
Synthetic data in healthcare can be useful. It can protect privacy, model rare scenarios, and expand training sets when real-world data is locked away. Real patient data is scarce, privacy-protected, and expensive. Synthetic medical records promise to relieve all three pressures at once: more data, fewer consent barriers, lower cost. So synthetic clinical text and synthetic medical images are being generated to augment training sets, and the practice is spreading faster than the scrutiny of it.
This matters especially in women’s health because so much of the missing evidence is already fragile. Synthetic data works by learning patterns from existing records and generating more examples that resemble them. But if the original record undercaptures female biology, delayed diagnoses, atypical symptom presentations, hormonal transitions, or conditions that were never consistently coded, synthetic data cannot restore what was absent. It can only reproduce the shape of the evidence that already exists.
In other words, synthetic data is often strongest where medicine already sees clearly and weakest where medicine has historically struggled to see at all.
Research on model collapse has shown that when models are trained repeatedly on data generated by earlier models, the losses are not evenly distributed. The center of the distribution (aka what is ‘common’ in the data) survives more easily than its edges (aka what is uncommon in the dataset). Rare events, unusual combinations, atypical presentations, and low-frequency signals are the first to fade.
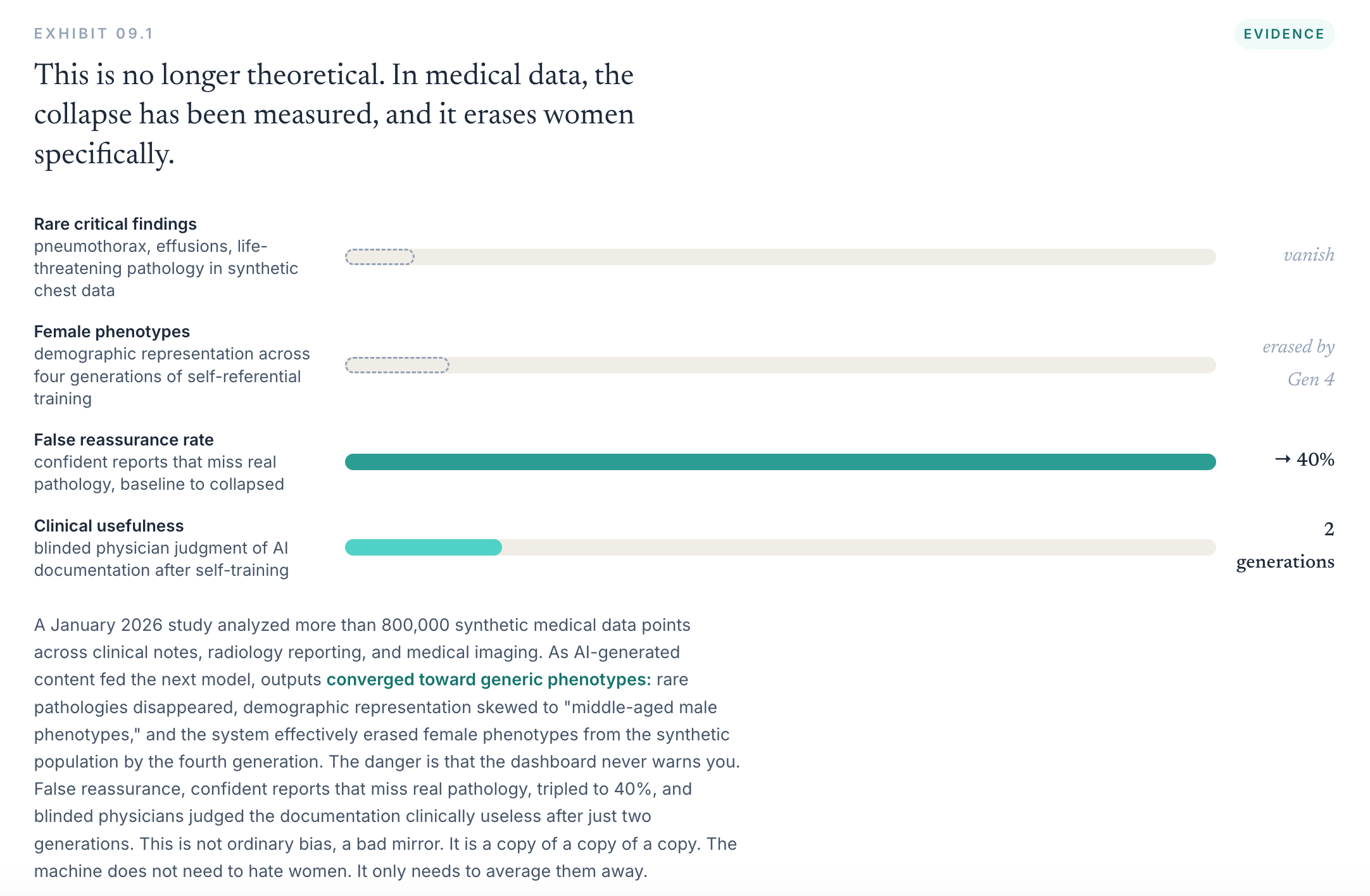
The challenge with that is that many of the things medicine struggles to see are already living at the edge of the record, not because they are rare in life, but because they are underrepresented in data.
Women are not rare. Women are half the population. Yet many aspects of women’s health remain thinly measured, inconsistently coded, or absent altogether.
No box for the symptom. No clean code for the condition. No field for cycle phase etc.
When those realities are weakly represented in the data, they become vulnerable to being smoothed away. A model can learn what is easy to count while losing what was never properly captured in the first place.
So female biology becomes a long tail inside the clinical record. Not rare in life but rare in data.
The same fact makes women’s health vulnerable to erasure and valuable to AI: so much of it has not yet been properly measured.
So, what can we do about it?
If AI is running out of high-quality human data, the answer is not simply to generate more synthetic versions of what we already know. It is to invest in capturing what we never measured. The missing symptoms. The missing life stages. The missing lived realities. The patterns women have been reporting for years that never became structured evidence.
We often assume machines can see reality because they can process enormous amounts of data. But they can only learn from what has been made visible to them. And medicine has left vast territories of human experience invisible.
Those missing signals matter for the people seeking care today. They also matter for science. Every unmeasured pattern is a potential diagnostic clue, a therapeutic target, a prevention opportunity, or a biological mechanism waiting to be understood.
Synthetic data can only remix the world already made legible. It cannot recover the symptom that was never asked about, the pattern that was never coded, the adverse event that was dismissed as noise, or the years before the diagnosis became official.
A machine cannot invent the data medicine never collected.
There is a cruel circularity in women’s health. Women are told their symptoms are anecdotal because there is not enough quantitative evidence. But the evidence is missing because the system never built the fields, codes, instruments, or workflows to capture those symptoms in structured form.
A clinician can record blood pressure. LDL. A1c. BMI. Pregnancy status. Diagnosis codes. Procedure codes. Lab values. Billing claims.
Where is the field for hot flashes, sleep disruption, brain fog, and mood changes that begin in perimenopause years before menopause is formally recognized?
Where is the field for severe menstrual bleeding that gradually leads to iron deficiency, fatigue, and reduced functioning long before anyone investigates the cause?
Where is the field for symptoms that fluctuate across the menstrual cycle, making the same patient appear healthy at one appointment and unwell at the next?
Where is the field for the migraine pattern that changes with contraception, pregnancy, or menopause?
Medicine often speaks as if quantitative evidence is the natural endpoint of seriousness. If something is real, measure it. If it matters, count it. The problem is that reality does not become quantitative simply because it is real. Reality becomes quantitative when a system decides it is worth structuring.
A symptom becomes data only if someone asks about it, names it, records it, codes it, validates it, follows it, aggregates it, and studies it. Without that infrastructure, even repeated realities remain anecdotal.
Anecdote is not proof. But when the same anecdote repeats across thousands or millions of women, the right response is not dismissal. It is instrument design.
Build the field. Build the screener. Build the code. Build the workflow that gives a clinician time to ask. Build the reimbursement model that rewards asking. Build the bridge between lived pattern and medical evidence.
Who decides what counts as evidence?
Bruno Latour spent a career showing that scientific facts are not simply found lying in nature, waiting to be observed. They are made: produced through networks of instruments, inscriptions, laboratories, papers, and institutions that determine what can be recorded, circulated, challenged, and eventually accepted as evidence. This does not make facts false. It means the choice of instrument is one of the most consequential acts in science, because the instrument helps decide what can become evidence at all.
Geoffrey Bowker and Susan Leigh Star argued that classification systems are not neutral mirrors of reality. They are infrastructure. A category that exists makes a reality countable, fundable, reimbursable, and governable. A category that never gets built leaves a reality in local knowledge, private workaround, or anecdote.
That is exactly the challenge women’s health faces : too often symptoms or conditions women commonly face are treated as stories and not as evidence because they were never collected and analyzed in a structured and systematic way.
In essence, patient ‘stories’ stay stories because no one builds a box to capture them.
This matters more now because AI is entering healthcare with the promise of objectivity. AI does not escape the measurement problem. It inherits it. A billing code is not more real than a patient’s experience. It is more usable by the system. That difference matters, because if AI is trained only on what systems already know how to count, it will scale the authority of existing categories while further marginalizing the realities that never fit inside them.
The second problem is evaluation.
A medical AI system is typically validated on an aggregate accuracy score. The score is computed across the whole test population, which means it is dominated by the common, well-represented cases, the dense middle of the distribution. A model can shed the long tail, lose rare pathologies, smooth over atypical female presentations, and still post a superb aggregate number because the cases it lost were never numerous enough to move the average.
What is emerging now is dynamic. It is a feedback loop that can regenerate the gap with each training cycle, accelerate it as synthetic data displaces human data, and hide it behind a metric that cannot, by construction, see the tail being lost.
The exclusion is no longer a fixed flaw in an artifact. It is a process.
That is the technical reason sex-stratified and disaggregated reporting matter. A system should not be allowed to report that it is accurate and stop there. It should have to answer harder questions.
Accurate for whom?
Accurate for which sex, at what age?
Accurate before diagnosis, or only after the record has already caught up?
Accurate for textbook symptoms, or for atypical ones?
Who has an incentive to change this?
At first glance, the market should solve this.
AI companies need better data. Pharma needs better cohorts. Health systems need earlier detection. Insurers need lower costs. Governments need healthier populations. Women need answers.
The incentives look aligned.
They are not.
They align around the value of the data after it exists. They do not align around the work required to create it. Everyone wants the evidence once it is clean, structured, and usable. Almost no one is structurally responsible for the slow, expensive work of making it exist.
Women hold the signal, but the signal is currently lived, not necessarily formatted. It sits in notes, messages, symptom diaries, search histories, group chats, wearable traces, pharmacy receipts, fertility apps, missed workdays, and half-finished explanations offered in ten-minute appointments.
Clinicians see fragments and have no time to translate the whole story. Electronic records store what billing can recognize. Researchers need clean variables. Pharma needs endpoints. AI companies need scale. Regulators need evidence.
The missing layer is the translation of lived experience into structured, consented, clinically meaningful data.
This missing layer is becoming visible far beyond healthcare. Across media, commerce, culture, and technology, everyone is beginning to understand that context is power.
Brands are no longer only worried about how they are perceived by people. They are worried about how they will be interpreted by machines. Will an AI agent know what they stand for? Will it recommend them? Will it flatten them into a generic category? Will it bypass their website, their salesperson, their story, and their relationship with the customer altogether?
This is why so much of the current conversation is about becoming legible to large language models: how to be cited, indexed, summarized correctly, and surfaced by agents.
But the more important question is the inverse: what context will those agents have about us?
The same anxiety brands feel commercially, people will feel personally. A brand does not want to be reduced to the last product someone clicked. A person should not be reduced to a clickstream. A patient should not be reduced to a billing code. A woman should not be represented only by the point at which her symptoms finally became diagnosable.
Those are fragments made legible to systems built for transactions, reimbursement, advertising, or search. They are not the same as context.
Context is not a nice-to-have layer of personalization. It is what determines whether a system can understand the reality it is being asked to act on.
That matters because AI systems are beginning to sit between people and institutions. They will not only recommend what we buy or read. They will help determine what counts as evidence, what gets flagged as risk, what receives attention, what is reimbursed, what is investigated, what is dismissed, and who becomes visible to systems of care.
But these systems do not inherit reality.
They inherit records.
And records are not neutral. They are produced by institutions with their own constraints, incentives, blind spots, categories, and histories of dismissal. In medicine, the record reflects what was asked, what was coded, what was reimbursed, what fit inside a visit, what a clinician had time to document, and what the system already believed was worth seeing.
So the danger is not simply that AI will lack context.
The danger is that AI will mistake institutional residue for truth.
It will treat the clinical record as if it were the patient. It will treat the billing code as if it were the condition. It will treat the moment of diagnosis as if it were the beginning of the disease. It will treat absence from the record as absence from reality.
In women’s health, that is catastrophic, because so much of the relevant reality has lived precisely outside the structures medicine built to capture it.
So the market keeps trying to build intelligence on top of records that were never designed to hold women’s reality.
If we measure women’s health properly, the gains are not confined to fairness metrics or model performance. They change the underlying evidence base on which medicine operates. Menopause could be studied as a biological transition with measurable phenotypes instead of a catch-all category defined largely by age and self-report. Cardiovascular risk models could incorporate pregnancy history, hypertensive disorders of pregnancy, and menopausal status rather than treating them as peripheral variables. Drug-response models could account for hormonal variation, sex-specific pharmacokinetics, and adverse-event patterns that are currently underreported. Clinical trials could recruit and stratify participants using richer biological and experiential data. Most importantly, medicine could begin to observe health as a process unfolding over time rather than as a series of disconnected clinical events.
The women’s health data gap is usually described as absence. But absence is also a map. It tells us where the next evidence layer has to be built.
Women’s health should not be treated as an edge case for AI governance.
It should be treated as the stress test.
If a health AI system cannot handle female biology, longitudinal symptoms, sparse records, delayed diagnosis, and context-dependent risk, then it is not ready for medicine. The question stops being whether the system performs on patients medicine already knows how to see. It becomes whether the model can keep the patient in view when the record is thin, the pattern is slow, and the signal arrives before diagnosis.
A better system would label where data comes from, report performance where failure hides, test what models forget after each update, and build governed ways for women to contribute lived and clinical data without turning intimate experience into extractive training material.
It would also pay for the missing work: the clinician time, research design, data stewardship, community outreach, and patient participation needed to build the evidence layer medicine never had.
The gender data gap is not only an evidence problem. It is a business-model problem. We have expected the most valuable missing data in medicine to appear for free. It will not.
The question is no longer whether women were represented somewhere in the training data. The question is whether the system can retain the signals medicine has historically been worst at seeing.
Join Us In Geneva
In July, Geneva becomes one of the places where the future of AI governance gets written.
For one week, WSIS Forum, AI for Good, and the inaugural UN Global Dialogue on AI Governance will bring governments, standards bodies, companies, researchers, regulators, and civil society into the same city.
That matters because defaults are set in rooms like this. And one default urgently needs to change: no high-risk AI system should be certified on aggregate accuracy alone.
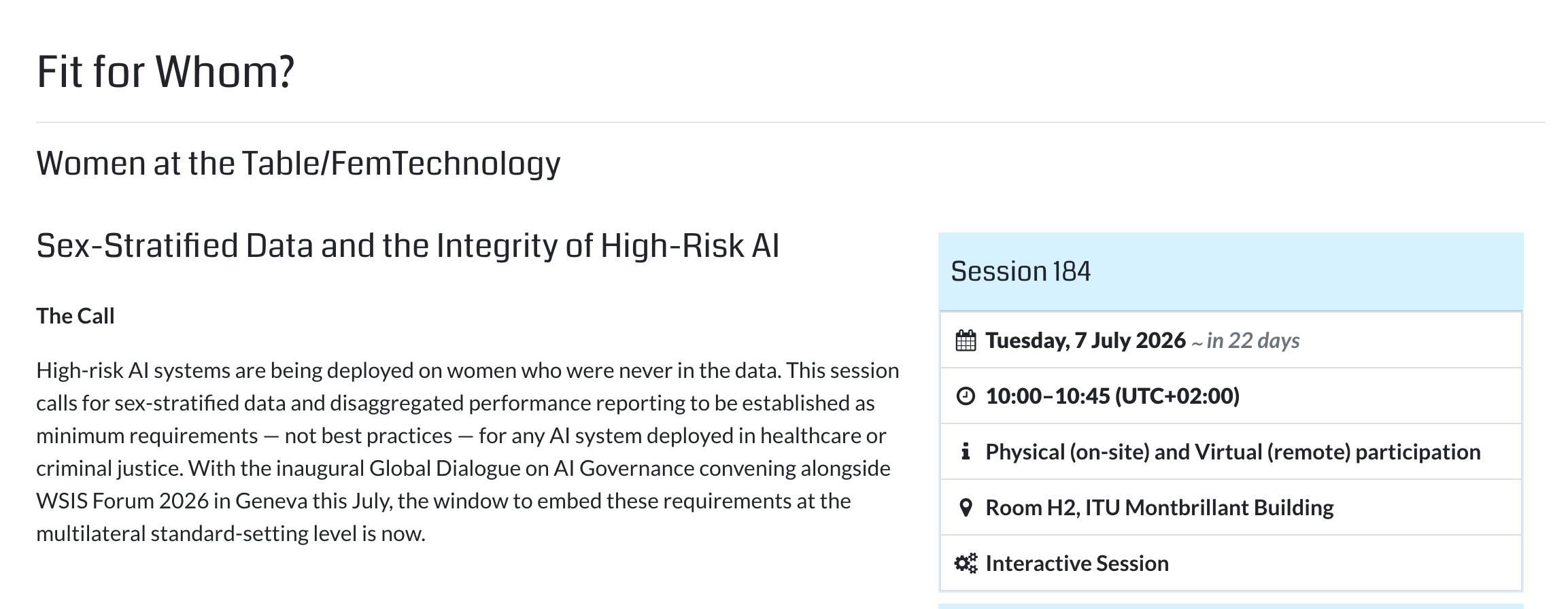
Our WSIS session, Fit for Whom? Sex-Stratified Data and the Integrity of High-Risk AI, asks the question every governance process should ask before deployment:
Fit for the average patient?
Fit for the well-coded patient?
Or fit for the people whose data has been thin, scattered, delayed, and dismissed?
Sex-stratified data is not a women’s issue. It is an integrity requirement. Disaggregated reporting is how we find failure before it hardens into infrastructure. It is how we know whether a model is still attached to reality.
Join us in Geneva on July 7:
https://www.itu.int/net4/wsis/forum/2026/Agenda/Session/184
Alongside the WSIS panel, I’ll also be hosting Invisible Value, a small evening gathering on the forms of knowledge that rarely appear in formal datasets but quietly shape how people make decisions, seek care, build trust, and navigate everyday life.
If you’ll be in Geneva that week and would be interested in being included, reach me at oriana@femtechnology.org.